

Are there any recommended best practices for scaling the Censys Python API calls?
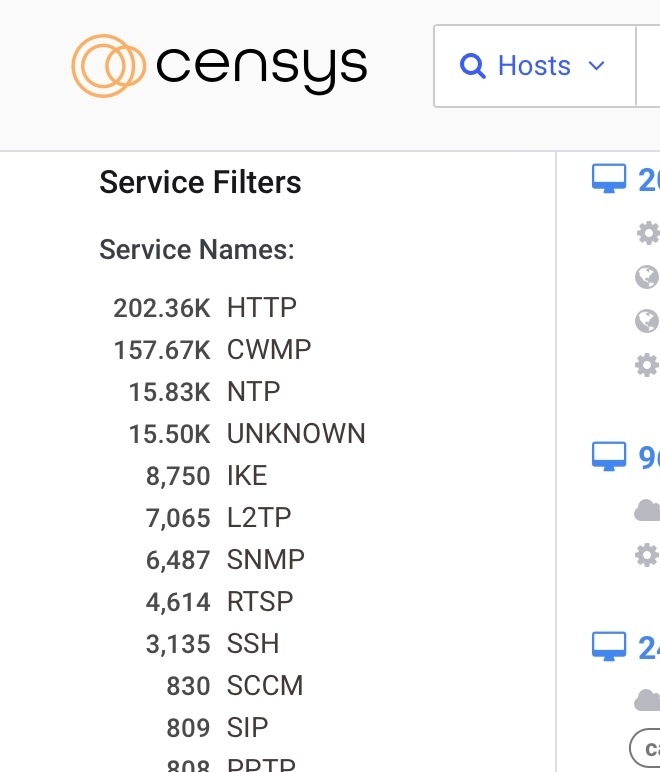
I am interested in the CWMP protocol. The following query will return 10k of the 157k. If I ran this daily search to track that service, I would quickly burn through the allocated quota.
query = h.search("services.service_name: CWMP", per_page=100, pages=100)
Does the road map contain feasible bulk or stream API options for large data sets?